
こんにちは、SUNABACOのカンパネルラです。
TwitterのAPIがめちゃくちゃ使いやすくなっていたのでbotを作りました。
経緯
ミュークルドリーミーというサンリオの作品(ブランド?)があって、2020年4月からアニメ第1期が、2021年4月からアニメ第2期が放送されていた。
放送期間中、ミュークルドリーミー公式Twitterアカウントからは毎日ミュークルじゃんけんというじゃんけんの動画がツイートされていた。
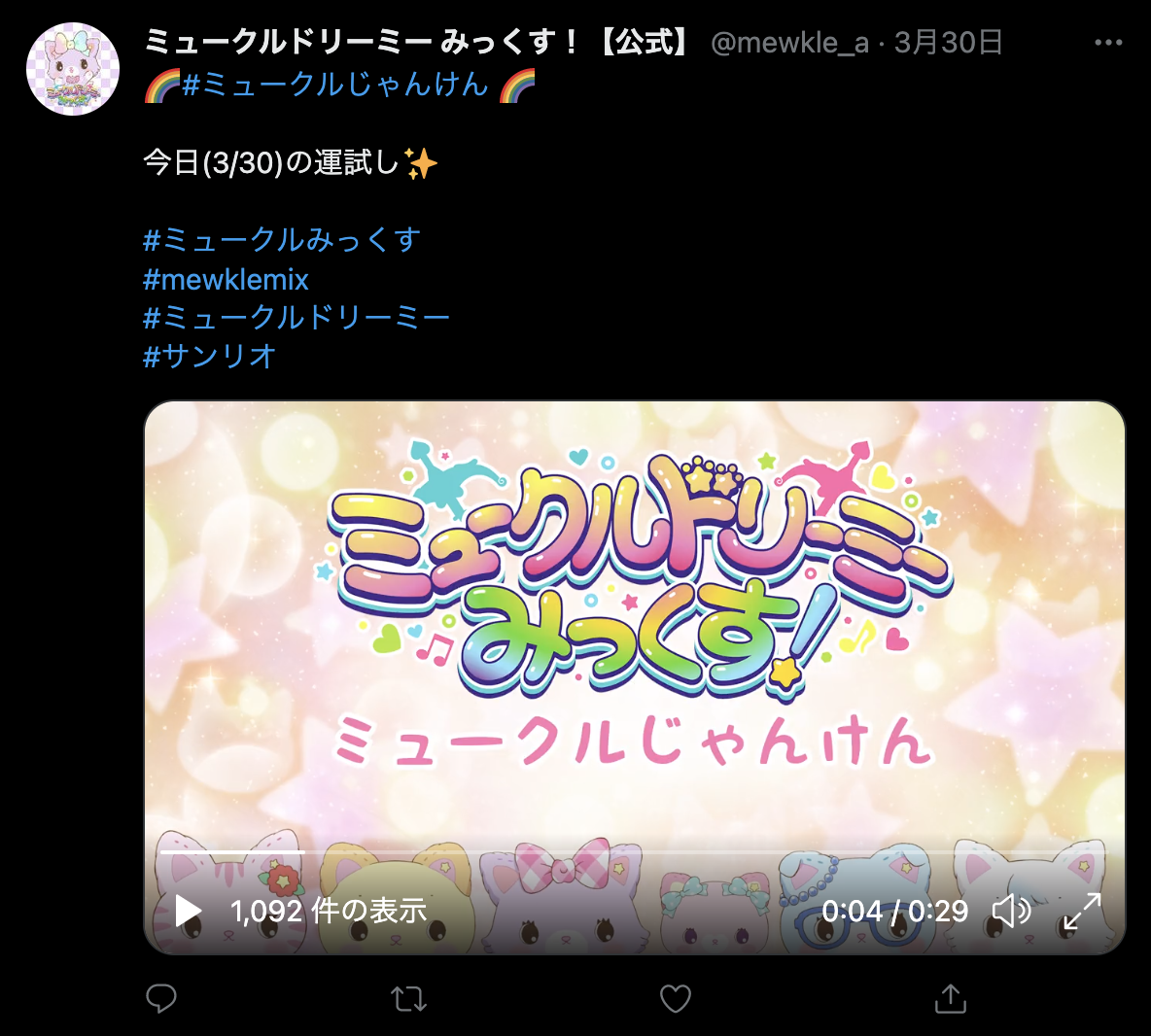
ところが、アニメの放送終了に伴い、ミュークルじゃんけんも終了することが発表された。
これは困る。ミュークルじゃんけん難民が発生して街がミュークルじゃんけんホームレスに溢れ、ミュークルじゃんけんの配給を待つ長蛇の列ができてしまう。
ということで、たまたまミュークルじゃんけん公式のじゃんけんの統計を取っていたこともあってミュークルじゃんけんを投稿するだけのbotを一晩で作成してミュークルじゃんけん投稿が1日たりとも途切れないようにすることにした。
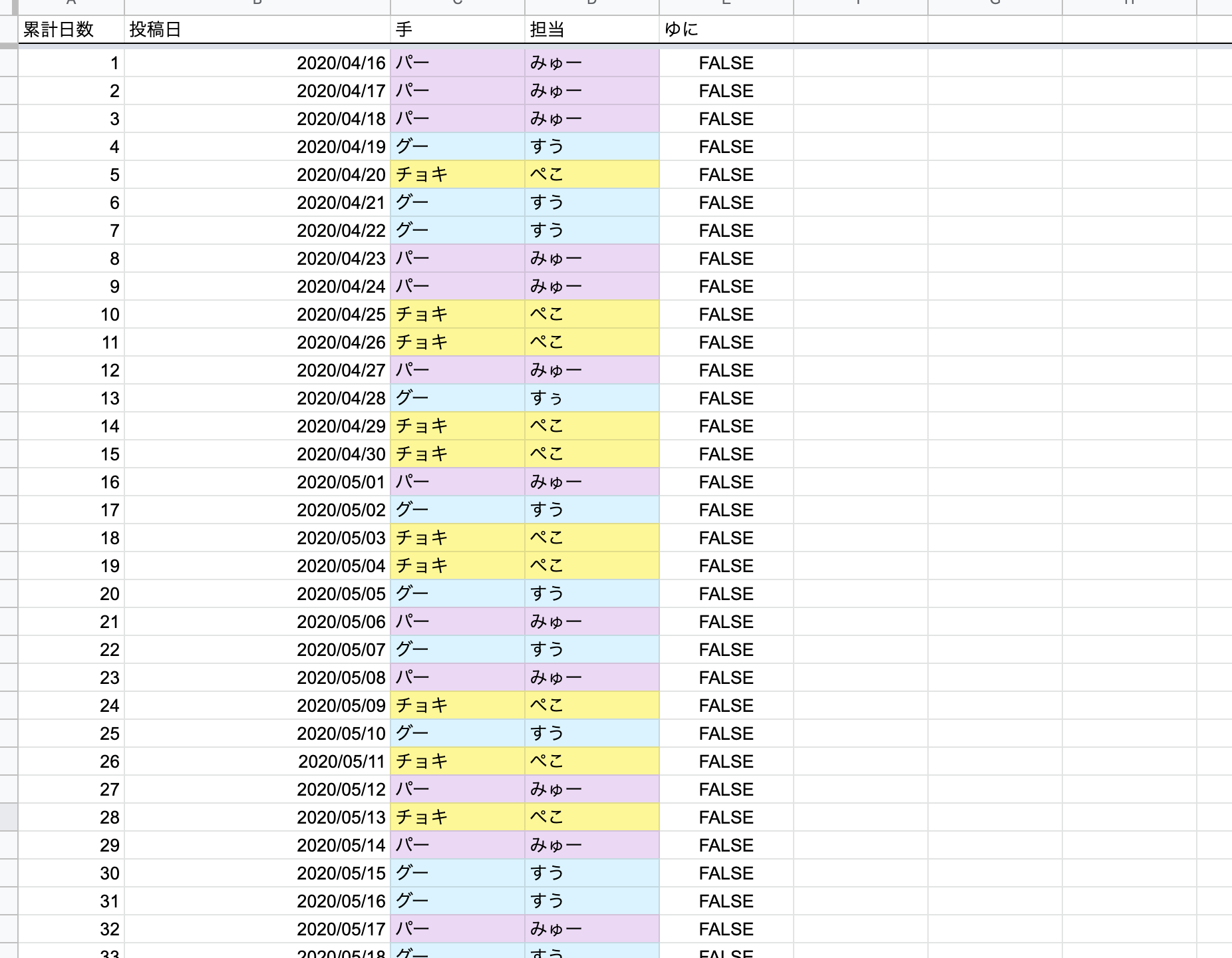
↑たまたま取っていたじゃんけんのデータ。PWAにしてスマホから統計情報を確認できるようにもしたりした。
結果
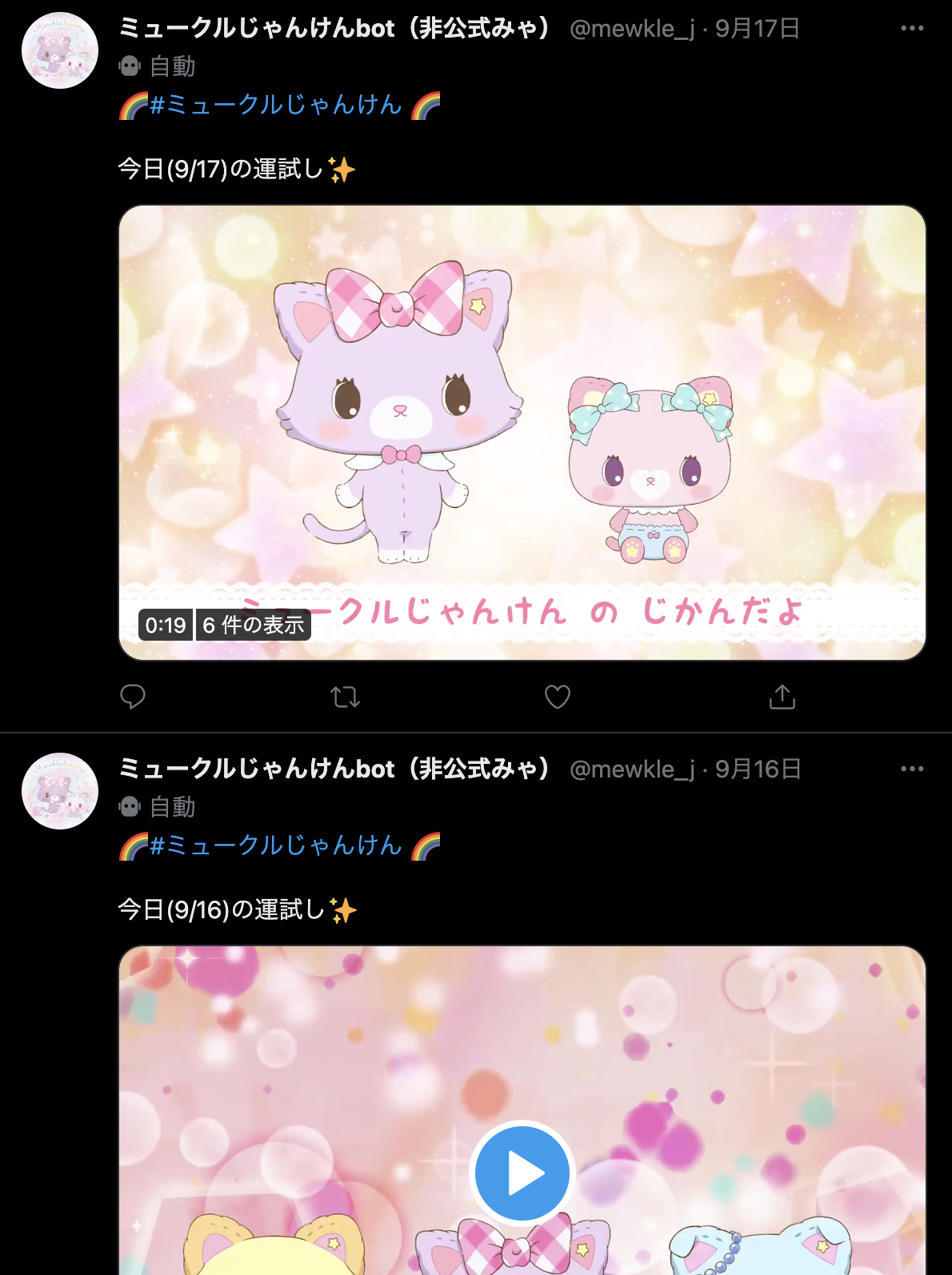
非公式のミュークルじゃんけんbotを作成し、毎日同時刻に投稿がされるようにした。
アカウントはこちら
Twitter APIに登録
はじめにTwitter APIに登録していく。
昔は登録しようとしたら英語で長文で利用用途を書いて、Twitterから質問が来るからそれにまた英語で返信して……みたいな感じで死ぬほど大変な上に、一度リジェクトされると二度とそのアカウントでは再登録できないというTwitter社はTwitterアカウントの重みを知らないのか?って感じの仕様だったのですが、最近超絶簡単に登録できかつ再申請可能になりました。ありがとう。でも最初からそうしてほしかった。
はじめに以下のTwitter API DocumentationのページなどからSign upのページに行く。
https://developer.twitter.com/en/docs/twitter-api
用途はmaking a botでいいとおもう。
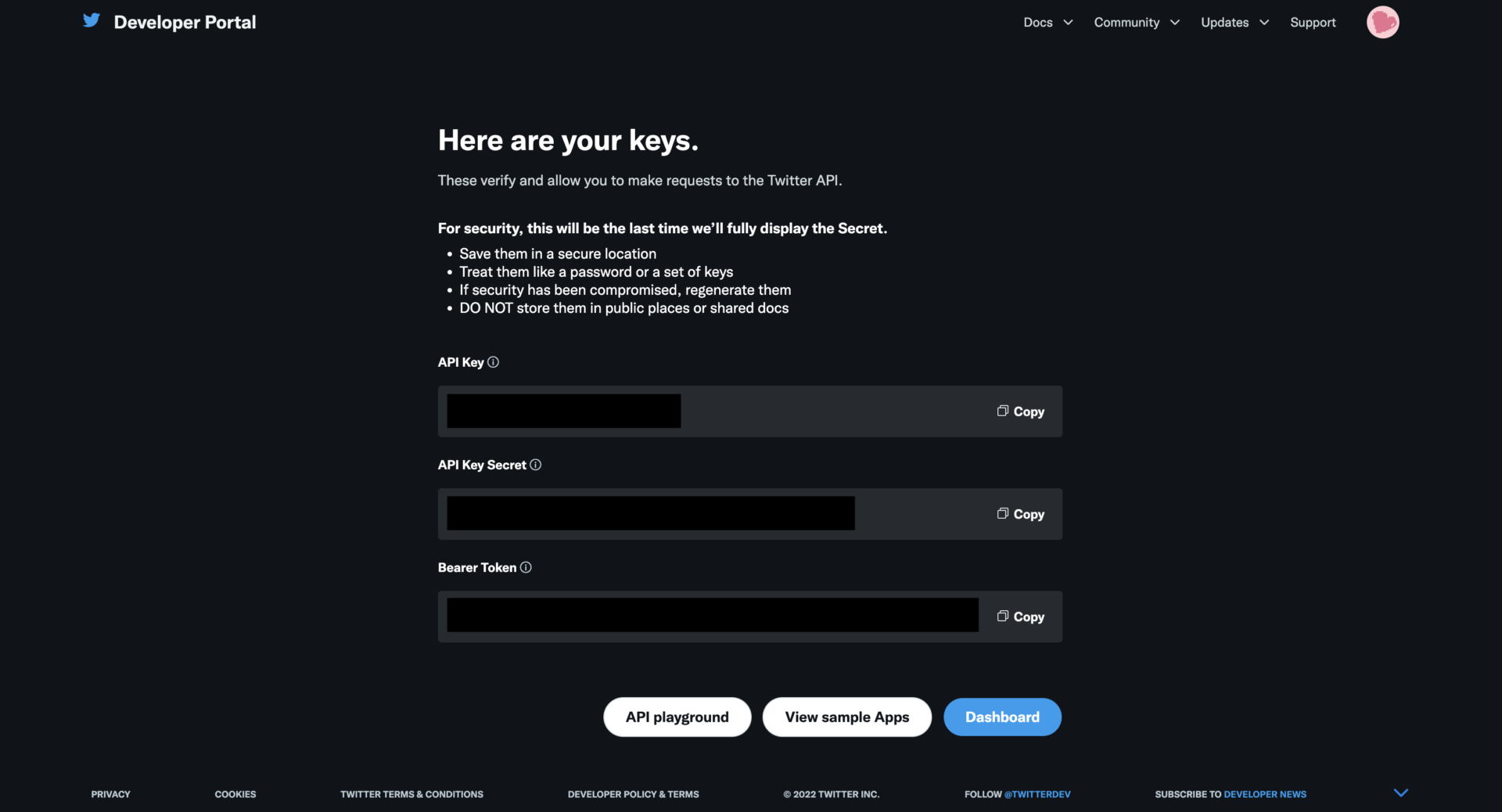
アプリの名前を入力すると、API Keyが表示されるのでメモしておく。
使うのはAPI KeyとAPI Key Secretになる。
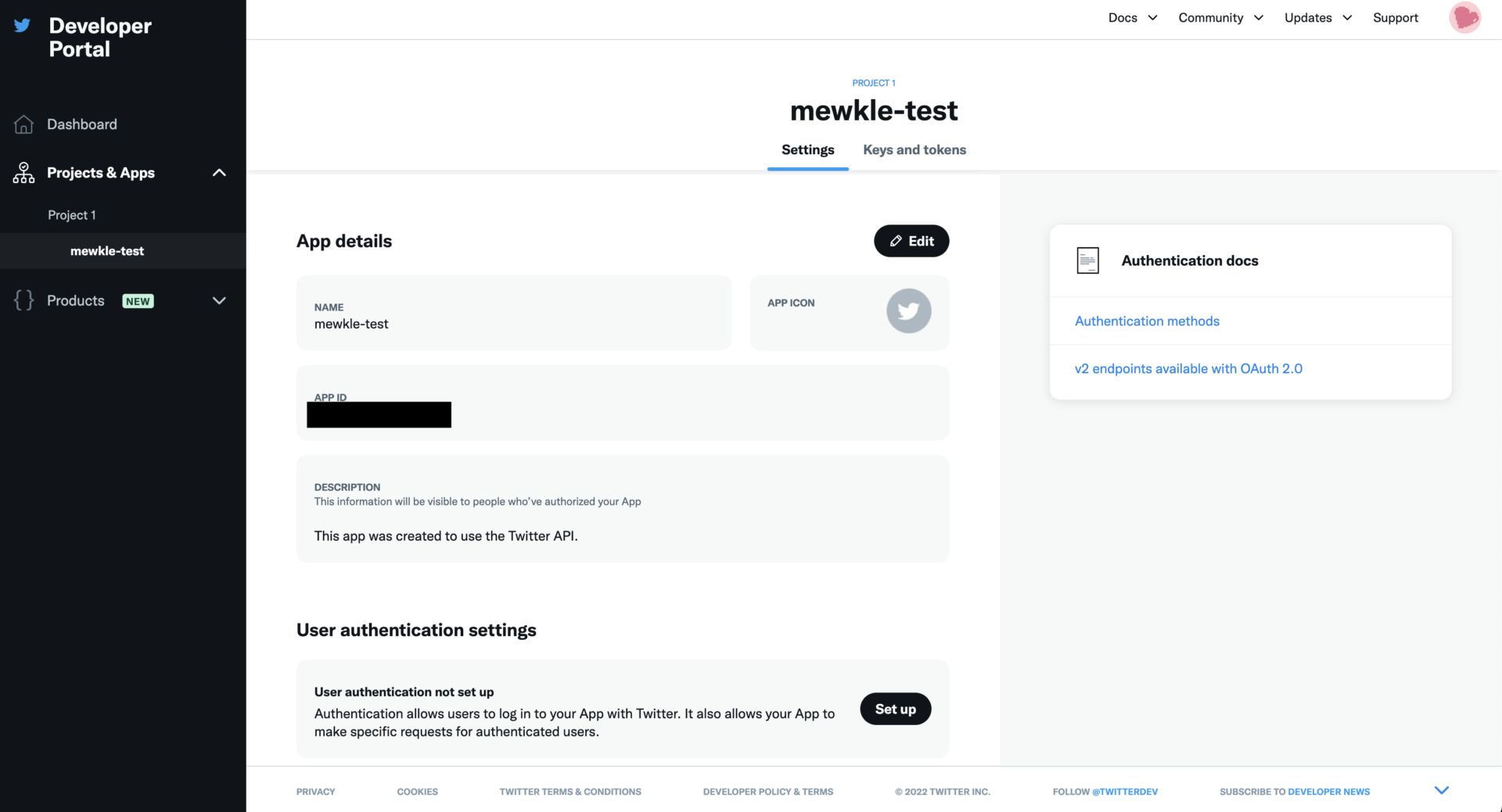
Developer Portalに進むので、Project&Appsの中のアプリ名をクリックし、authentication settingsのsign upを押す。
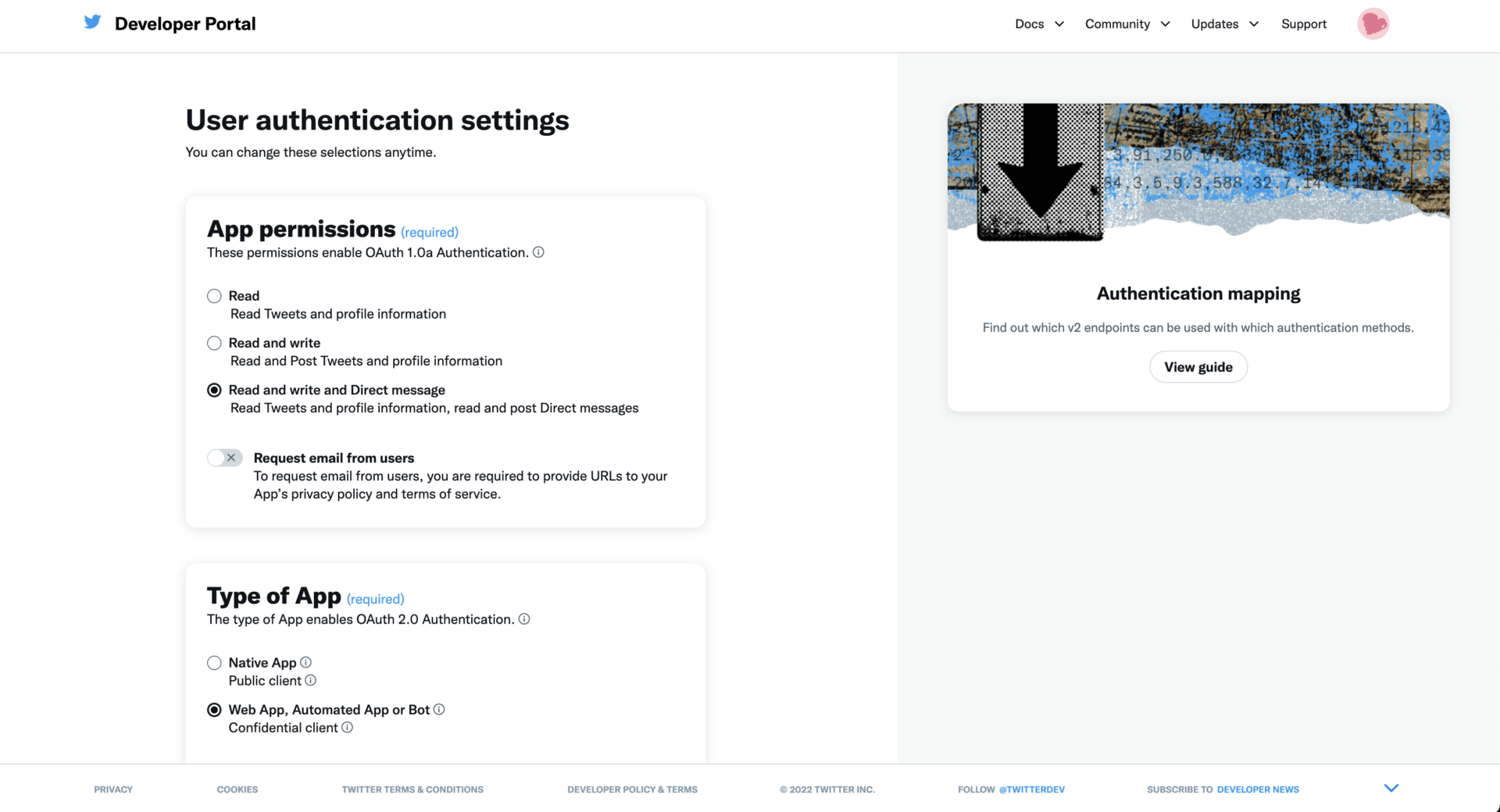
設定はpermissionsを一番下、typeはbotにしておく。(こうしないと権限レベルが変わってツイートできないっぽい)
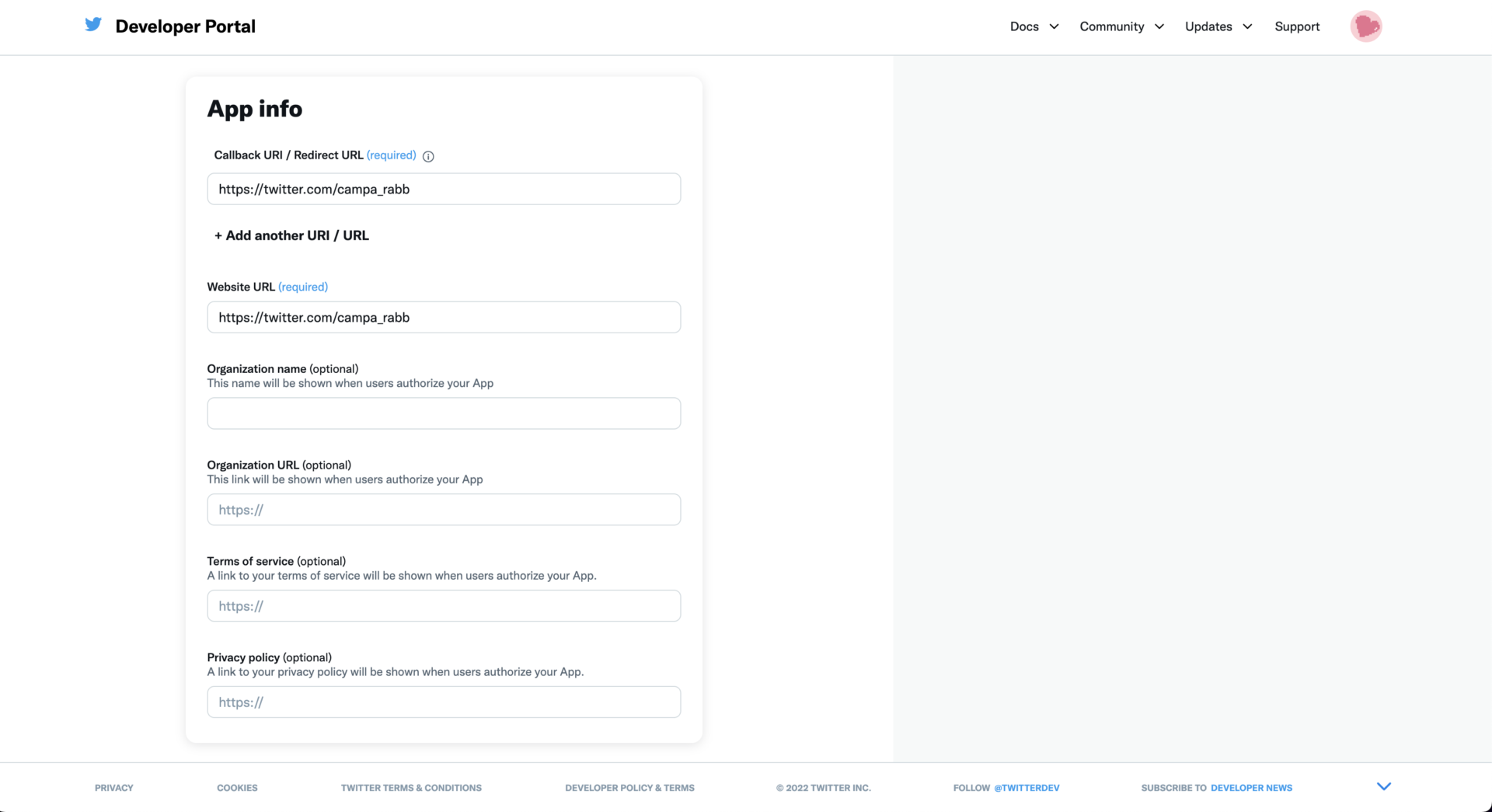
callback URLはbotの場合アカウントのプロフィールURLで問題ないっぽい。
だがこれだけだと動画ツイートの権限まではもらえないようなので、Products>Twitter API v2>Elevated>ApplyからElevated権限に昇格させる。
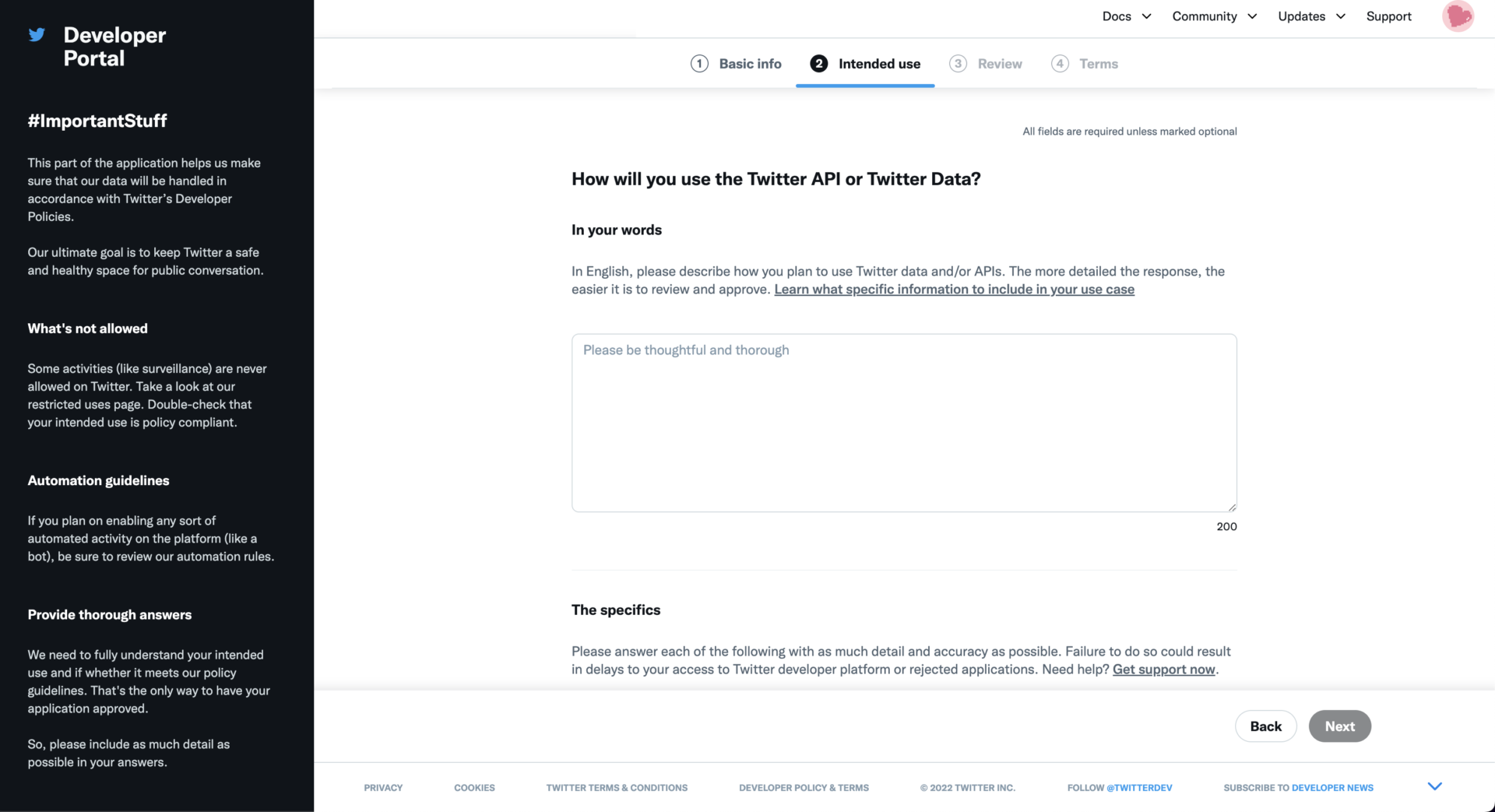
そして結局めちゃくちゃめんどくさいが英語でAPIの利用目的を200文字以上で書く。
昔と違って割と適当に書いてもリジェクトされなかったので、DeepL翻訳とか使いながら適当に作文する。ツイートの投稿以外は全部「利用しない」でいい。
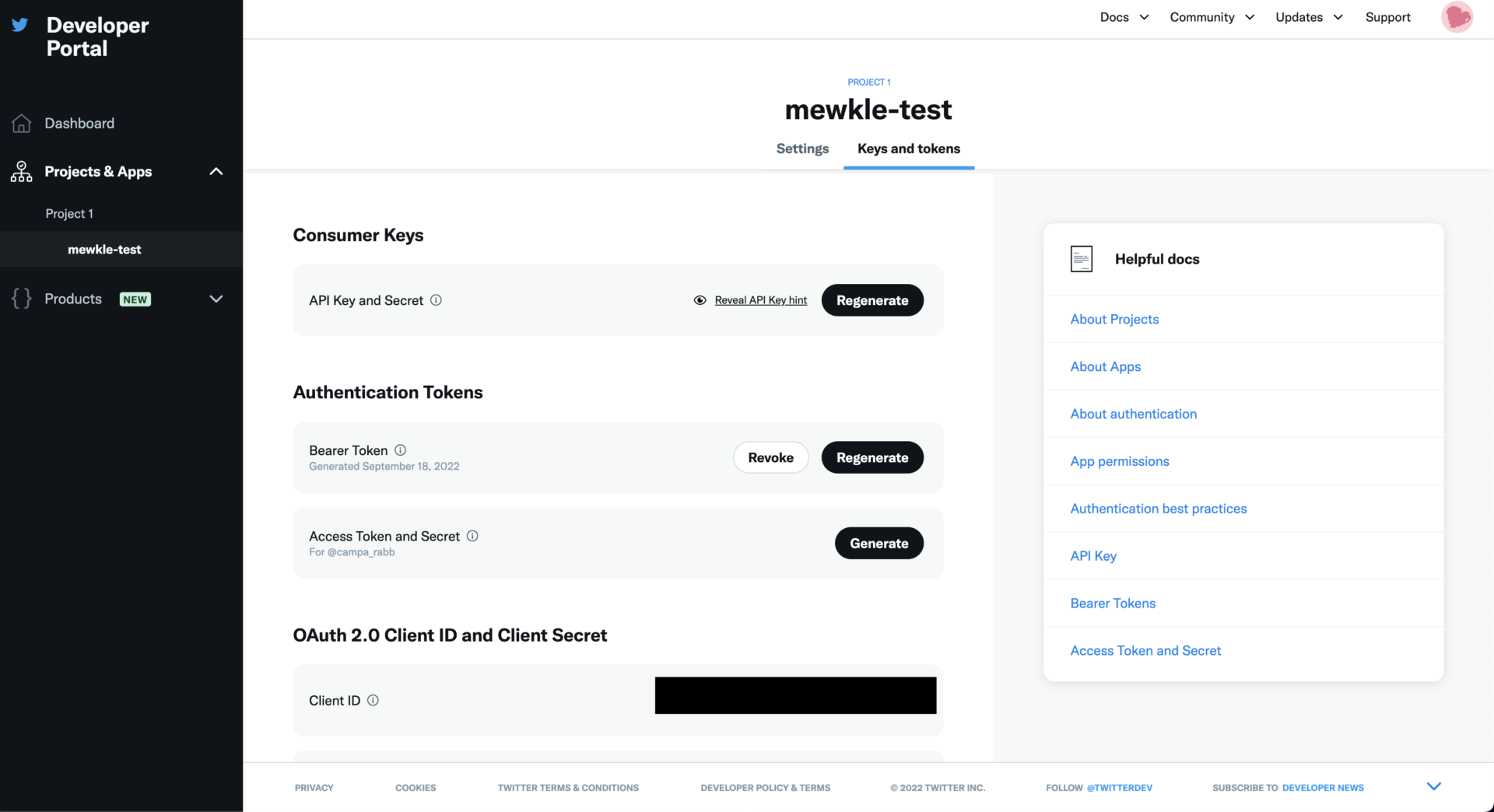
elevated権限に昇格できたら、アプリを選択し、Keys and tokensからAccess TokenとSecretをGenerateし、コピーしておく。
これでTwitter APIのほうは準備完了。
Pythonで投稿のソースコードを書く
ソースコード全体はGitHubに上げてるのでそちらを。
クローンしてきてHerokuに投げて環境変数にAPI Key入れたら動く。
https://github.com/campa-rabb/mewkle-janken
# 動画を読み込み
movie01 = "./movie/01_グー_ゆに.mp4"
movie02 = "./movie/02_グー_すう.mp4"
movie03 = "./movie/03_チョキ_ゆに.mp4"
movie04 = "./movie/04_チョキ_ぺこ.mp4"
movie05 = "./movie/05_パー_ゆに.mp4"
movie06 = "./movie/06_パー_みゅー.mp4"
movie07 = "./movie/07_みゅーちあ_グー.mp4"
movie08 = "./movie/08_みゅーちあ_チョキ.mp4"
movie09 = "./movie/09_みゅーちあ_パー.mp4"
movie10 = "./movie/10_ぺこすう_グー.mp4"
movie11 = "./movie/11_ぺこすう_チョキ.mp4"
movie12 = "./movie/12_ぺこすう_パー.mp4"
movie13 = "./movie/13_ねねれい_グー.mp4"
movie14 = "./movie/14_ねねれい_チョキ.mp4"
movie15 = "./movie/15_ねねれい_パー.mp4"
movie16 = "./movie/16_ゆにつぎはぎ_グー.mp4"
movie17 = "./movie/17_ゆにつぎはぎ_チョキ.mp4"
movie18 = "./movie/18_ゆにつぎはぎ_パー.mp4"
Azure blob storageなりに上げようかとも思ったけどめんどかったので、動画ファイルは全部脳死でいっしょに突っ込んだ。
# 動画を抽選
items = [movie01, movie02, movie03, movie04, movie05, movie06, movie07, movie08, movie09, movie10, movie11, movie12, movie13, movie14, movie15, movie16, movie17, movie18] # 内容
prob = [0.05, 0.11, 0.05, 0.1, 0.06, 0.11, 0.05, 0.05, 0.04, 0.04, 0.04, 0.03, 0.05, 0.05, 0.04, 0.05, 0.04, 0.04] # 確率
N = 1 # 回数
result = np.random.choice(items, N, p=prob)
numpyでそれぞれの動画ごとに確率を設定して抽選している。
確率は過去のミュークルじゃんけんの2年分の毎日投稿を全投稿手動でチェックして集計した。
Azure Cognitive Servicesに投げて一定秒数の画像を分析すれば自動で解析もできる気がするけど考えるのがめんどくさかった。(エンジニアとしてどうなん?)
# アップロードする動画ファイルのパス
VIDEO_FILENAME = result[0]
MEDIA_ENDPOINT_URL = 'https://upload.twitter.com/1.1/media/upload.json'
POST_TWEET_URL = 'https://api.twitter.com/1.1/statuses/update.json'
# Twitter APIの認証情報を設定
# APP_ENVがPRDなら本番の認証情報、DEVなら開発の認証情報を使う
APP_ENV = os.environ.get('APP_ENV')
if APP_ENV == "PRD":
CONSUMER_KEY = os.environ.get("CONSUMER_KEY")
CONSUMER_SECRET = os.environ.get("CONSUMER_SECRET")
ACCESS_TOKEN = os.environ.get("ACCESS_TOKEN")
ACCESS_TOKEN_SECRET = os.environ.get("ACCESS_TOKEN_SECRET")
else:
CONSUMER_KEY = os.environ.get("CONSUMER_KEY_DEV")
CONSUMER_SECRET = os.environ.get("CONSUMER_SECRET_DEV")
ACCESS_TOKEN = os.environ.get("ACCESS_TOKEN_DEV")
ACCESS_TOKEN_SECRET = os.environ.get("ACCESS_TOKEN_SECRET_DEV")
# API認証
oauth = OAuth1(CONSUMER_KEY,
client_secret=CONSUMER_SECRET,
resource_owner_key=ACCESS_TOKEN,
resource_owner_secret=ACCESS_TOKEN_SECRET)
# 動画ツイートのclass
class VideoTweet(object):
def __init__(self, file_name):
'''
Defines video tweet properties
'''
self.video_filename = file_name
self.total_bytes = os.path.getsize(self.video_filename)
self.media_id = None
self.processing_info = None
def upload_init(self):
'''
Initializes Upload
'''
print('INIT')
request_data = {
'command': 'INIT',
'media_type': 'video/mp4',
'total_bytes': self.total_bytes,
'media_category': 'tweet_video'
}
req = requests.post(url=MEDIA_ENDPOINT_URL, data=request_data, auth=oauth)
media_id = req.json()['media_id']
self.media_id = media_id
print('Media ID: %s' % str(media_id))
def upload_append(self):
'''
Uploads media in chunks and appends to chunks uploaded
'''
segment_id = 0
bytes_sent = 0
file = open(self.video_filename, 'rb')
while bytes_sent < self.total_bytes:
chunk = file.read(4*1024*1024)
print('APPEND')
request_data = {
'command': 'APPEND',
'media_id': self.media_id,
'segment_index': segment_id
}
files = {
'media':chunk
}
req = requests.post(url=MEDIA_ENDPOINT_URL, data=request_data, files=files, auth=oauth)
if req.status_code < 200 or req.status_code > 299:
print(req.status_code)
print(req.text)
sys.exit(0)
segment_id = segment_id + 1
bytes_sent = file.tell()
print('%s of %s bytes uploaded' % (str(bytes_sent), str(self.total_bytes)))
print('Upload chunks complete.')
def upload_finalize(self):
'''
Finalizes uploads and starts video processing
'''
print('FINALIZE')
request_data = {
'command': 'FINALIZE',
'media_id': self.media_id
}
req = requests.post(url=MEDIA_ENDPOINT_URL, data=request_data, auth=oauth)
print(req.json())
self.processing_info = req.json().get('processing_info', None)
self.check_status()
def check_status(self):
'''
Checks video processing status
'''
if self.processing_info is None:
return
state = self.processing_info['state']
print('Media processing status is %s ' % state)
if state == u'succeeded':
return
if state == u'failed':
sys.exit(0)
check_after_secs = self.processing_info['check_after_secs']
print('Checking after %s seconds' % str(check_after_secs))
time.sleep(check_after_secs)
print('STATUS')
request_params = {
'command': 'STATUS',
'media_id': self.media_id
}
req = requests.get(url=MEDIA_ENDPOINT_URL, params=request_params, auth=oauth)
self.processing_info = req.json().get('processing_info', None)
self.check_status()
def tweet(self):
'''
Publishes Tweet with attached video
'''
d_today = datetime.date.today()
format_date = d_today.strftime('%-m/%-d')
request_data = {
'status': f'''🌈#ミュークルじゃんけん 🌈
今日({format_date})の運試し✨''',
'media_ids': self.media_id
}
req = requests.post(url=POST_TWEET_URL, data=request_data, auth=oauth)
print(req.json())
# ツイートを実行
if __name__ == '__main__':
# 本番環境の場合、時刻外ツイートを避ける処理を念の為入れている
if APP_ENV == "PRD":
dt_now = datetime.datetime.now()
if datetime.time(6,50,00) < dt_now.time() < datetime.time(7,15,00):
videoTweet = VideoTweet(VIDEO_FILENAME)
videoTweet.upload_init()
videoTweet.upload_append()
videoTweet.upload_finalize()
videoTweet.tweet()
else:
print("時間外に実行されました")
# 開発環境の場合そのまま実行
else:
videoTweet = VideoTweet(VIDEO_FILENAME)
videoTweet.upload_init()
videoTweet.upload_append()
videoTweet.upload_finalize()
videoTweet.tweet()
このへんはほとんどtwitterdevが公開してくれている動画ファイルのツイートのコードをそのまま使っている。
https://github.com/twitterdev/large-video-upload-python/blob/master/async-upload.py
公式が書いてるだけあって美しい……。
一応、専用のアカウントに投稿している関係上環境変数に「PRD」が入っている時だけ本番のアカウントのAPI keyが使われるようにしている。
あと本番環境の時だけ現在時刻を取得して時間外投稿を防ぐようにしてある。
環境変数はpython-dotenvで管理しているので、このへんはお好みで変えてください。
ちなみにpython-dotenvを使ったときの.envファイルはこんな感じ。
# ローカルか本番か
APP_ENV = "PRD"
# 本番環境のTwitter API認証情報
CONSUMER_KEY = 'API Keyを入れる'
CONSUMER_SECRET = 'API Key Secretを入れる'
ACCESS_TOKEN = 'Access Tokenを入れる'
ACCESS_TOKEN_SECRET = 'Access Token Secretを入れる'
# 開発用のAPI認証情報
CONSUMER_KEY_DEV = 'API Keyを入れる'
CONSUMER_SECRET_DEV ='API Key Secretを入れる'
ACCESS_TOKEN_DEV = 'Access Tokenを入れる'
ACCESS_TOKEN_SECRET_DEV = 'Access Token Secretを入れる'
本番環境じゃない時はAPP_ENVをLOCALとか適当な値に変えたら本番のアカウントのAPI Keyは使われなくなる。
このへんの本番環境との切り分けは割とオレオレ実装なので、もっといいやり方があったら教えてください。
デプロイ
Herokuの無料プラン廃止が発表されたので今からやるのは微妙かもしれないが、これをデプロイしたときは無料プラン廃止の発表前だったのでHerokuにデプロイしている。
Heroku Schedulerが大変優秀なので、毎日実行はそれだけで実現できている。
Herokuへのデプロイはたぶんめちゃくちゃ記事があるので割愛。
環境変数だけちゃんと設定してあげてください。
worker: python post.py
Procfileは上記。web dynoだと確か処理時間が一定を超えるとタイムアウトされるというのもあって、今回はworker dynoを使うのがいいと思う。
まとめ
Herokuは慣れていたのもあってここまでを隙間時間で一晩で実装できた。
以前ならTwitter APIが承認されるまでに数週間はみないといけなかったので、Twitterのbotがアカウントの作成から始めて思いついたときにすぐ作れるのはいいな〜と思う。
余談だけど、Twitterのヘルプセンターによると完全なbotはbot表示が義務とのことだったのでそこだけ注意しておきましょう。(知らずに数ヶ月運用してたけど特にbanはされなかった)
https://help.twitter.com/ja/using-twitter/automated-account-labels
分からないことがあったらカンパネルラにTwitterで聞くかSUNABACOのAPIコースに来てください。(宣伝)