
機械学習には「教師あり学習」と「教師なし学習」と呼ばれるものがあります。

機械学習は正直高度な知識なので、難しいと感じる人は多いと思います。数学に関してもなかなか詳しくないと深くまでは理解できないですし……
とはいえ、この記事を読めば子供や上司に「教師あり学習ってなに?」って聞かれたときに、誰でも説明できるようになりますので、安心してください。
教師あり学習とは
教師あり学習とは、学習データに正解を与えた状態で学習させる手法です。代表的なのが、「回帰」と「分類」です。
回帰とは、連続する数値を予測するものです。平均気温や来客数などのデータとお弁当の販売個数の関係を学習し、将来のお弁当の販売個数を予測する、といったものが回帰にあたります。
気温によって店にくる数とか年齢とかが異なりますよね。そこから実際にどのくらいお弁当が売れたのかの関係データから、明日何人来るかを予測する、みたいなことです!

例えば、上のような画像データも、画像の特徴量を取り出して、猫の場合や仮面の場合の画像の特徴を抽出して学習していきます。
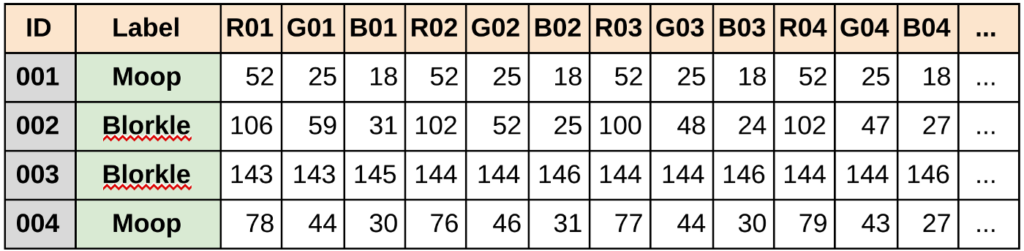
画像データは直感的にデータが理解しにくいと思いますが、pixelごとに抽出するような感じですね。テーブルにすると上記のような感じ。そうすると、画像によって特徴がありますよね。
教師ありデータの場合は、人間がすでに正解のデータ(ラベルづけ)をしてあり、それを比較しながら学習していきます。
ラベル
ここでラベルは正解のことです。 このような写真を表示するときに、出力されたものをコンピュータ学習させたいのです。
「正しいデータ」という名の教師(=ラベル)を用いて、そこに新たに不明なデータ(画像なら猫なのか仮面なのか犬なのかわからない画像)を持ち寄った際には、そのデータの正体の正解を教えてくれる(=予測する)という感じです。正解となる膨大なデータを学習すればするほど、その予測精度が上がります。
特徴量
画像の特徴ってなんだよって思うかもしれませんが、例えばピクセルの色ですね。人間は異なり、コンピューターは画像をきれいな光ではなく数字として見ます。表示されているのは、画像の左上隅から始まり、下に向かってみていき、ピクセルを赤、緑、青の値でとらえます。その羅列が上記のテーブルの画像です。
これに慣れてくると、あなたはデジタル写真を見るたびに、データを分析し、一連の数字として保存されているものとして認識、理解できるでしょう。
あなたはすでにデータアナリストです!
これらのピクセル値は、コンピューターが学習する入力値です。機械学習というかっこいい言葉が使われていますが、やっていることは「入力」、「変数」、「予測子」などを使って学習と予測をしているだけです。
あなたにおすすめ記事▼